进阶 - 在线服务
Published on
简介
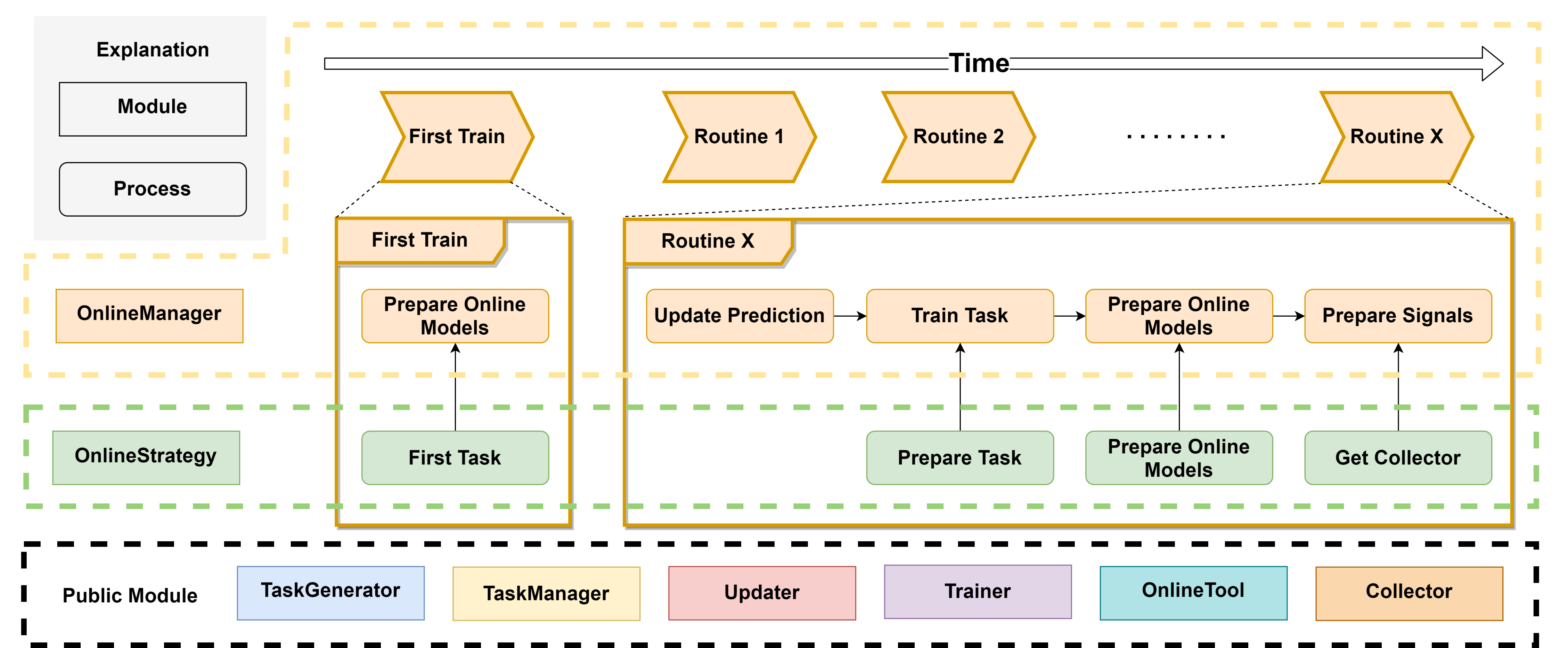
一般情况下,Qlib使用静态的配置文件或代码定义模型、数据集与训练任务,如果它们有任何改变,则需要修改配置文件或代码并重新运行任务。但是频繁地进行此操作过于繁琐,为此,Qlib提出了在线服务功能,通过事先定义配置文件模板,此功能可以自动更新配置文件并重新运行任务。其架构图如下:
这里有一些可供参考的例子,它们展示了在线服务的不同特性。
在线管理器
在线管理器可以管理一组在线策略并动态地运行它们。
随着时间变化,模型也会变化。在本模块中,这些模型被称为在线模型。在每个例行程序(如每天或每分钟)中,在线模型可能有变化,因此它们的预测也需要更新,所以本模块提供一系列方法来控制这个过程。本模块也提供一个方法以在历史上仿真在线策略,这意味着可以验证策略或找到一个更好的策略。
在不同的情况下使用不同的训练器的组合一共有4种:
- 在线+训练器:当想要运行真实例行程序时,训练器会帮助逐任务逐策略地训练模型
- 在线+延迟训练器:在所有策略都准备好任务后,延迟训练器才会开始训练,这使用户可以在
routine或first_train结束后并行地训练所有任务;在策略准备好任务前,这些函数会阻塞 - 仿真+训练器:与第一种组合表现相同,唯一区别是本组合用于仿真/回测而不是在线交易
- 仿真+延迟训练器:在模型没有时间依赖时,可以使用延迟训练器的多任务能力。这意味着在仿真结束时,所有例行程序中的所有任务都会被真正地训练。根据是否有新模型在线,信号会在不同的时间段准备好
下面是演示每种情况工作流的伪代码。其中做了以下简化:
- 只使用了一个策略
update_online_pred只有在在线模式才会被调用
在线+训练器:
tasks = first_train()
models = trainer.train(tasks)
trainer.end_train(models)
for day in online_trading_days:
# OnlineManager.routine
models = trainer.train(strategy.prepare_tasks()) # 对于每个策略
strategy.prepare_online_models(models) # 对于每个策略
trainer.end_train(models)
prepare_signals() # 每天准备交易信号
在线+延迟训练器:与在线+训练器的工作流相同
仿真+延迟训练器:
# 仿真
tasks = first_train()
models = trainer.train(tasks)
for day in historical_calendars:
# OnlineManager.routine
models = trainer.train(strategy.prepare_tasks()) # 对于每个策略
strategy.prepare_online_models(models) # 对于每个策略
# delay_prepare()
# FIXME: 目前delay_prepare没有用合适的方式实现
trainer.end_train(<for all previous models>)
prepare_signals()
在线策略
本模块是在线服务的一个元素。
在线工具
本模块是一个设置与取消设置一系列在线模型的模块。在线模型是在某些时间点上的决策模型,它们可以随时间变化而变化。这允许我们随着市场风格变化使用高效的子模型。
更新器
本模块在股票数据更新时,更新预测等输出信息。