进阶 - 强化学习
Published on
简介
与监督学习(如分类或回归)不同,强化学习是另一种重要的机器学习范式,它尝试在马尔可夫决策过程等假设下通过直接与环境互动来最大化累积奖励。此处不介绍强化学习本身的内容,只介绍Qlib中与之相关的内容。Qlib提供了一个强化学习工具箱QlibRL,它是一个针对量化投资的强化学习平台。
量化交易中的使用场景
在投资的场景中,投资者通过买卖操作来管理他们的仓位,以努力优化投资回报率。投资者在每次做出买卖决策之前,都会小心地评估市场条件与股票信息。从投资者的视角,这个过程可以看作由市场交互驱动的连续决策过程。强化学习算法为应对此类挑战提供了有前景的方法,下面是强化学习算法在量化投资领域的一些可能的应用场景:
订单执行
订单执行任务需要在考虑多种目标因素的同时高效地执行订单,这些因素包括:最优化价格、最小化交易成本、减小市场冲击、最大化订单完成率,以及在特定时间范围内完成执行。通过将这些目标结合为奖励函数与动作选择过程,就可以在此类任务上使用强化学习算法。具体来说,强化学习智能体与市场环境进行交互,观察市场当前状态,并对下一步执行做出决策。强化学习算法通过试错学习出一个最优执行策略,以达到最大化累积奖励的目的,从而实现想要的目标。
- 基本设定
- 环境:代表发生订单执行的市场,包含订货簿、流动性、价格走势与市场状况等变量
- 状态:表示强化学习智能体在某一时刻能够获取的信息,通常包括当前订货簿状态(买卖价差、订货簿深度)、历史价格、历史成交量、市场波动率以及其它任何可以帮助进行决策的信息
- 动作:指强化学习智能体基于可以观察到的状态所做出的决策。在订单执行任务中,动作包括选择订单大小、价格与执行时间
- 奖励:是一个表示强化学习智能体动作性能的标量信号。奖励函数被设计为鼓励那些导致高效率、低成本的订单执行的动作。它通常考虑多个目标,例如最大化价格优势、最小化交易成本(包括手续费与滑点)、减小市场冲击(订单对市场价格的影响)以及最大化订单完成率。
- 场景
- 单资产订单执行:聚焦于在单个资产上执行单个订单的任务。主要目标是在高效执行订单的同时考虑最大化价格优势、最小化交易成本、减小市场冲击以及最大化订单完成率等因素。强化学习智能体与市场环境交互并对指定资产的订单大小、价格与执行时间做出决策。目标是学习出一个能够在考虑单个资产特性的同时最大化累积奖励的最优执行策略
- 多资产订单执行:将订单执行任务扩展到多个资产上,需要同步地或顺序地执行跨资产的订单组合。不仅需要聚焦于执行单个订单,还要管理资产组合中不同资产间的相互作用与依赖。强化学习智能体需要对资产组合中每个资产的订单大小、价格与执行时间做出决策,同时考虑它们的相互依赖性、现金约束、市场状况及交易成本。目标是学习出一个可以平衡每个资产的执行效率,同时能将整个资产组合作为一个整体考虑其总体性能与目标的最优执行策略
资产组合构建
资产组合构建是在一个资产组合中选择与分配资产的过程。强化学习提供了一个优化资产组合管理决策的框架,它从与市场环境的互动中学习,并在考虑风险的同时最大化长期回报。
- 基本设定
- 状态:代表市场与资产组合的当前信息,通常包括历史价格与成交量、技术指标与其它相关数据
- 动作:对应将资金分配给不同资产的决策,决定了每个资产的投资权重或比率
- 奖励:评估投资组合表现的指标,可以通过不同的方式定义,如总回报率、无风险回报率,或其它目标如最大化夏普比率、最小化回撤
- 场景
- 股票市场:将强化学习用于构建股票的投资组合,智能体学习将资金分配给不同的股票
- 加密货币市场:将强化学习用于构建加密货币的投资组合,智能体学习资金分配决策
- 外汇市场:将强化学习用于构建货币对的投资组合,智能体学习基于汇率数据、经济指标和其它因素在不同货币间分配资金
例子
QlibRL提供了一个例子,实现了一个单资产订单执行任务,下面是其训练配置文件:
simulator:
# Each step contains 30mins
time_per_step: 30
# Upper bound of volume, should be null or a float between 0 and 1, if it is a float, represent upper bound is calculated by the percentage of the market volume
vol_limit: null
env:
# Concurrent environment workers.
concurrency: 1
# dummy or subproc or shmem. Corresponding to `parallelism in tianshou <https://tianshou.readthedocs.io/en/master/api/tianshou.env.html#vectorenv>`_.
parallel_mode: dummy
action_interpreter:
class: CategoricalActionInterpreter
kwargs:
# Candidate actions, it can be a list with length L: [a_1, a_2,..., a_L] or an integer n, in which case the list of length n+1 is auto-generated, i.e., [0, 1/n, 2/n,..., n/n].
values: 14
# Total number of steps (an upper-bound estimation)
max_step: 8
module_path: qlib.rl.order_execution.interpreter
state_interpreter:
class: FullHistoryStateInterpreter
kwargs:
# Number of dimensions in data.
data_dim: 6
# Equal to the total number of records. For example, in SAOE per minute, data_ticks is the length of the day in minutes.
data_ticks: 240
# The total number of steps (an upper-bound estimation). For example, 390min / 30min-per-step = 13 steps.
max_step: 8
# Provider of the processed data.
processed_data_provider:
class: PickleProcessedDataProvider
module_path: qlib.rl.data.pickle_styled
kwargs:
data_dir: ./data/pickle_dataframe/feature
module_path: qlib.rl.order_execution.interpreter
reward:
class: PAPenaltyReward
kwargs:
# The penalty for a large volume in a short time.
penalty: 100.0
module_path: qlib.rl.order_execution.reward
data:
source:
order_dir: ./data/training_order_split
data_dir: ./data/pickle_dataframe/backtest
# number of time indexes
total_time: 240
# start time index
default_start_time: 0
# end time index
default_end_time: 240
proc_data_dim: 6
num_workers: 0
queue_size: 20
network:
class: Recurrent
module_path: qlib.rl.order_execution.network
policy:
class: PPO
kwargs:
lr: 0.0001
module_path: qlib.rl.order_execution.policy
runtime:
seed: 42
use_cuda: false
trainer:
max_epoch: 2
# Number of episodes collected in each training iteration
repeat_per_collect: 5
earlystop_patience: 2
# Episodes per collect at training.
episode_per_collect: 20
batch_size: 16
# Perform validation every n iterations
val_every_n_epoch: 1
checkpoint_path: ./checkpoints
checkpoint_every_n_iters: 1
下面是回测的配置:
order_file: ./data/backtest_orders.csv
start_time: "9:45"
end_time: "14:44"
qlib:
provider_uri_1min: ./data/bin
feature_root_dir: ./data/pickle
# feature generated by today's information
feature_columns_today: [
"$open", "$high", "$low", "$close", "$vwap", "$volume",
]
# feature generated by yesterday's information
feature_columns_yesterday: [
"$open_v1", "$high_v1", "$low_v1", "$close_v1", "$vwap_v1", "$volume_v1",
]
exchange:
# the expression for buying and selling stock limitation
limit_threshold: ['$close == 0', '$close == 0']
# deal price for buying and selling
deal_price: ["If($close == 0, $vwap, $close)", "If($close == 0, $vwap, $close)"]
volume_threshold:
# volume limits are both buying and selling, "cum" means that this is a cumulative value over time
all: ["cum", "0.2 * DayCumsum($volume, '9:45', '14:44')"]
# the volume limits of buying
buy: ["current", "$close"]
# the volume limits of selling, "current" means that this is a real-time value and will not accumulate over time
sell: ["current", "$close"]
strategies:
30min:
class: TWAPStrategy
module_path: qlib.contrib.strategy.rule_strategy
kwargs: {}
1day:
class: SAOEIntStrategy
module_path: qlib.rl.order_execution.strategy
kwargs:
state_interpreter:
class: FullHistoryStateInterpreter
module_path: qlib.rl.order_execution.interpreter
kwargs:
max_step: 8
data_ticks: 240
data_dim: 6
processed_data_provider:
class: PickleProcessedDataProvider
module_path: qlib.rl.data.pickle_styled
kwargs:
data_dir: ./data/pickle_dataframe/feature
action_interpreter:
class: CategoricalActionInterpreter
module_path: qlib.rl.order_execution.interpreter
kwargs:
values: 14
max_step: 8
network:
class: Recurrent
module_path: qlib.rl.order_execution.network
kwargs: {}
policy:
class: PPO
module_path: qlib.rl.order_execution.policy
kwargs:
lr: 1.0e-4
# Local path to the latest model. The model is generated during training, so please run training first if you want to run backtest with a trained policy. You could also remove this parameter file to run backtest with a randomly initialized policy.
weight_file: ./checkpoints/latest.pth
# Concurrent environment workers.
concurrency: 5
使用上面的配置文件,可以通过如下命令启动训练:
python -m qlib.rl.contrib.train_onpolicy.py --config_path train_config.yml
训练完成后,可以使用如下命令进行回测:
python -m qlib.rl.contrib.backtest.py --config_path backtest_config.yml
框架
QlibRL包含一套完整的组件,覆盖了包括建立市场仿真器、塑造状态与动作、在仿真环境中训练策略与回测策略的强化学习流水线的整个生命周期。QlibRL基于天授与Gym框架实现,其高层结构如下所示:
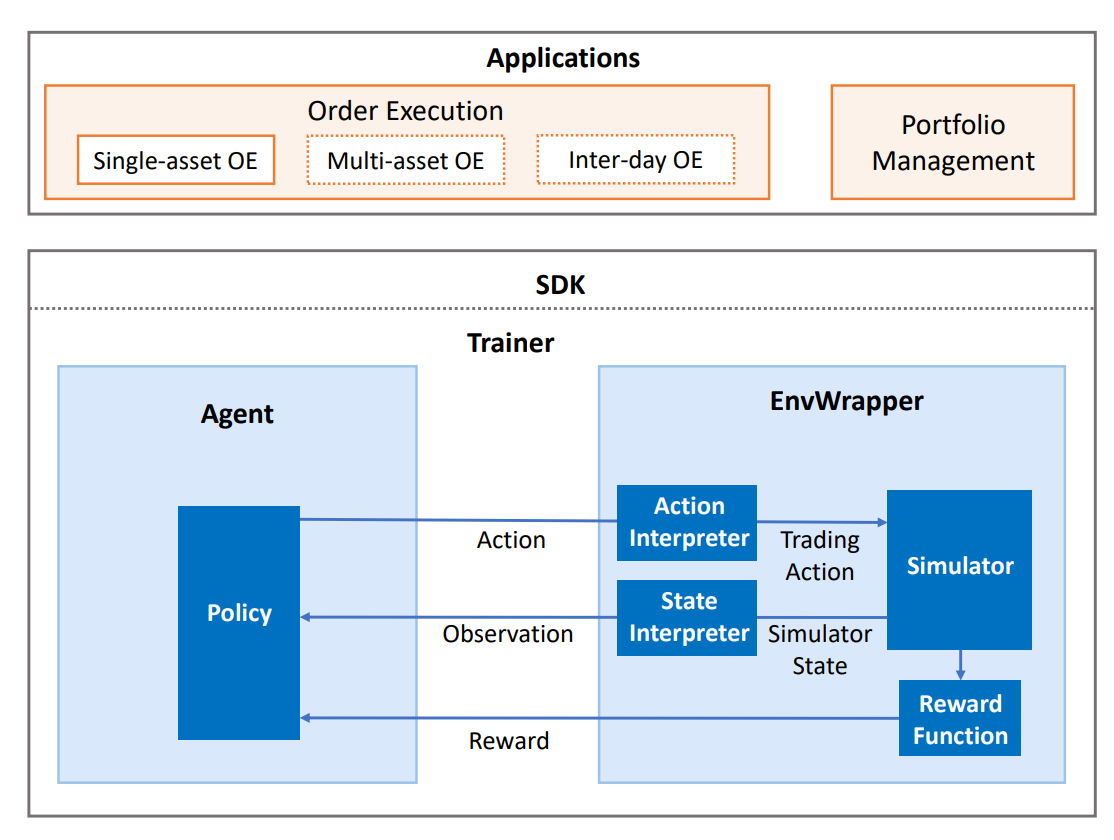
下面简要介绍每个组件:
环境 EnvWrapper
EnvWrapper是对仿真环境的完整封装。它从外部(策略/智能体)接收动作,在市场中模拟变化,之后返回奖励并更新状态,从而形成一个互动循环。
在QlibRL中,EnvWrapper是gym.Env的子类,因此实现了所有必需的接口。所有接收gym.Env的类或流水线也接收EnvWrapper。开发者无需为了建立环境实现自己的EnvWrapper,而只需实现EnvWrapper的4个组件即可:
- 仿真器 Simulator:负责环境仿真的核心组件。开发者可以以任何方式实现与环境仿真直接相关的所有逻辑。在QlibRL中已经实现了两个用于单资产交易的仿真器:
- SingleAssetOrderExecution:基于Qlib回测工具箱构建,考虑了许多实际交易细节,但是速度慢
- SimpleSingleAssetOrderExecution:基于简化的交易仿真器构建,忽略了许多细节(如交易限制、舍入),但是速度快
- 状态解释器 State interpreter:负责将原始格式(仿真器提供的格式)的状态解释为策略可以理解的格式,例如,将无结构原始特征转换为数值张量
- 动作解释器 Action interpreter:将策略生成的动作解释为仿真器可以接收的格式
- 奖励函数 Reward function:在每次策略执行一个动作后返回一个奖励值
EnvWrapper会将这些组件有机地组织起来。这样的分解可以在开发时得到更好的灵活性,例如,如果开发者要在一个相同的环境中训练多个类型的策略,只需设计一个仿真器并为每个类型的策略设计不同的状态解释器/动作解释器/奖励函数即可。QlibRL为以上组件均提供了基类,开发者只需继承基类并实现接口即可定义自己的组件。
策略 Policy
QlibRL直接采用天授的策略,开发者可以直接使用其现有策略,或继承其策略以实现自己的策略。
训练容器与训练器 Training Vessel & Trainer
训练容器与训练器是在训练中使用的辅助类。训练容器是一个包含仿真器/解释器/奖励函数/策略的容器,用于控制训练的算法相关部分。相应的,训练器负责控制训练的运行时部分。
可以注意到,一个训练容器持有建立一个环境的所有必需组件,但并不直接持有一个环境实例。这允许训练容器在必要时(如并行训练时)动态地建立多个环境副本。
与训练容器一起使用,训练器就可以通过类似Scikit-learn的简单接口启动训练流水线,如trainer.fit()。